De basis van crawl- en indexcontrole begrijpen
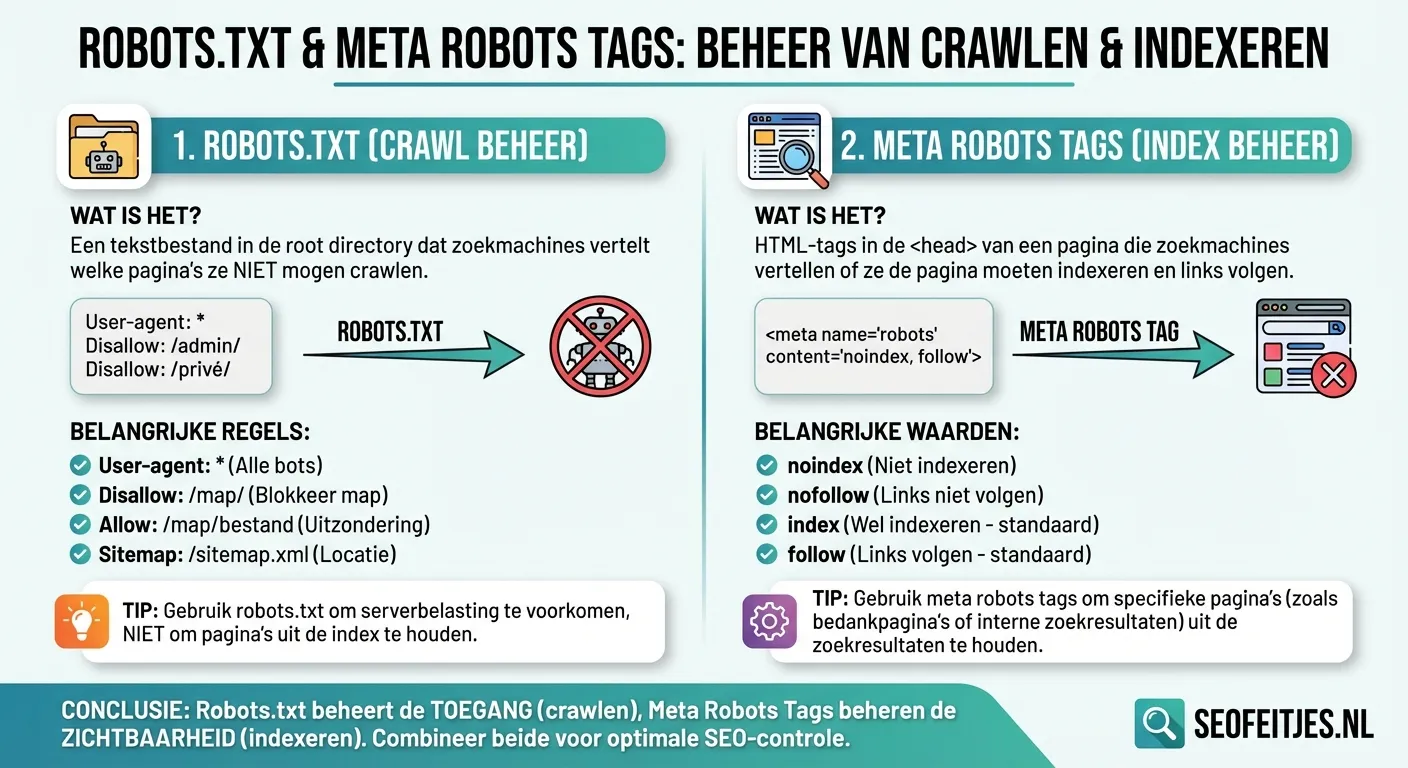
Het beheren van hoe zoekmachines je website crawlen en indexeren vormt een fundamenteel onderdeel van technische SEO. Zoekmachines zoals Google gebruiken twee belangrijke instrumenten om te bepalen welke pagina's ze wel of niet moeten verwerken: het robots.txt-bestand en meta robots tags. Deze tools vervullen verschillende maar complementaire functies in het grotere geheel van crawlbudget optimalisatie voor grote websites.
Het verschil tussen deze twee instrumenten is essentieel om te begrijpen. Het robots.txt-bestand fungeert als een poortwachter op domeinniveau en vertelt zoekmachinecrawlers welke delen van je website ze mogen bezoeken en welke niet. Meta robots tags daarentegen werken op paginaniveau en geven specifieke instructies over hoe zoekmachines met individuele pagina's moeten omgaan. Deze combinatie van controle-instrumenten stelt webmasters in staat om zeer gericht te sturen hoe hun content wordt verwerkt.
Volgens Google vormen deze instrumenten samen een krachtig systeem voor het optimaliseren van je website's zichtbaarheid in zoekresultaten. Bovendien helpen ze bij het efficiënt gebruiken van het beschikbare crawlbudget, waardoor zoekmachines zich kunnen concentreren op je meest waardevolle content.
Robots.txt: de poortwachter van je website
Het robots.txt-bestand vervult een cruciale rol als eerste aanspreekpunt voor zoekmachinecrawlers die je website bezoeken. Dit eenvoudige tekstbestand, dat zich altijd in de root van je domein bevindt (bijvoorbeeld www.jouwsite.nl/robots.txt), bepaalt welke delen van je website toegankelijk zijn voor crawlers. Daarbij is het belangrijk om te weten dat het blokkeren van crawling via robots.txt niet automatisch betekent dat een pagina niet geïndexeerd kan worden.
In de praktijk zie je vaak dat webmasters robots.txt gebruiken om bepaalde technische delen van hun website af te schermen. Denk hierbij aan administratiepanelen, interne zoekresultaatpagina's of tijdelijke testomgevingen. Het correct configureren van je robots.txt-bestand draagt significant bij aan een efficiëntere interne linkstructuur optimaliseren voor betere crawling.
Een veel voorkomende misvatting is dat robots.txt gebruikt kan worden om pagina's uit Google's index te houden. Echter, als andere websites naar je geblokkeerde pagina's linken, kunnen deze alsnog geïndexeerd worden. Daarom is het essentieel om robots.txt te combineren met meta robots tags voor volledige controle over indexering.
Meta robots tags: precisie-instructies voor zoekmachines
Meta robots tags bieden een verfijndere manier om zoekmachines te instrueren over hoe ze met specifieke pagina's moeten omgaan. Deze HTML-elementen worden in de head-sectie van individuele webpagina's geplaatst en kunnen verschillende directieven bevatten. De meest gebruikte zijn 'index/noindex' voor indexeringscontrole en 'follow/nofollow' voor het al dan niet doorgeven van linkwaarde.
Het grote voordeel van meta robots tags is hun precisie. Terwijl robots.txt werkt op mapniveau, kunnen meta tags exact aangeven wat er met elke individuele pagina moet gebeuren. Dit maakt ze bijzonder waardevol voor het optimaliseren van je sitemap XML optimalisatie voor efficiëntere crawling.
Een belangrijke nuance bij het gebruik van meta robots tags is dat ze alleen werken als de pagina daadwerkelijk gecrawld kan worden. Wanneer een pagina geblokkeerd is via robots.txt, zullen zoekmachines de meta robots tags niet kunnen lezen. Daarom is het cruciaal om een doordachte strategie te hebben waarbij beide instrumenten elkaar aanvullen in plaats van tegenwerken.
Praktische implementatie en veelgemaakte fouten
De implementatie van robots.txt en meta robots tags vereist zorgvuldigheid en aandacht voor detail. Een correct robots.txt-bestand begint altijd met het specificeren van de user-agent, gevolgd door allow- en disallow-regels. Het is daarbij essentieel om regelmatig te controleren of de syntax correct is, aangezien kleine typfouten grote gevolgen kunnen hebben voor je website's crawlbaarheid.
Meta robots tags kennen verschillende variaties en combinatiemogelijkheden. De meest voorkomende implementatie is <meta name="robots" content="noindex, follow">, waarbij 'noindex' voorkomt dat de pagina wordt opgenomen in zoekresultaten, maar 'follow' ervoor zorgt dat linkwaarde wordt doorgegeven naar gelinkte pagina's. Deze flexibiliteit maakt meta robots tags tot een krachtig instrument voor verfijnde SEO-strategieën.
Een veelgemaakte fout is het onbedoeld blokkeren van belangrijke pagina's door te algemene robots.txt-regels. Daarnaast zien we vaak dat webmasters vergeten hun implementaties te testen, wat kan leiden tot onverwachte indexeringsproblemen. Het is daarom aan te raden om regelmatig de Search Console te raadplegen voor mogelijke crawling- en indexeringsproblemen.
Monitoring en optimalisatie van crawl- en indexbeheer
Het implementeren van robots.txt en meta robots tags is slechts het begin. Continue monitoring en optimalisatie zijn essentieel voor effectief crawl- en indexbeheer. Google Search Console biedt hiervoor waardevolle inzichten via de Coverage-rapporten en de URL-inspectietool. Deze tools helpen bij het identificeren van problemen en het valideren van je implementaties.
Regelmatige audits van je robots.txt-bestand en meta robots tags zorgen ervoor dat je website optimaal gecrawld en geïndexeerd wordt. Let daarbij vooral op veranderingen in je websitestructuur die kunnen leiden tot nieuwe crawling-behoeften. Bovendien is het belangrijk om te monitoren of zoekmachines je instructies correct interpreteren en opvolgen.
De impact van correct crawl- en indexbeheer op je SEO-prestaties kan significant zijn. Door regelmatig te analyseren welke pagina's wel en niet geïndexeerd worden, kun je je strategie verfijnen en aanpassen aan veranderende omstandigheden. Dit draagt bij aan een gezondere technische basis voor je website.
Toekomstbestendige strategieën voor crawl- en indexbeheer
De wereld van zoekmachineoptimalisatie evolueert constant, en daarmee ook de beste praktijken voor crawl- en indexbeheer. Nieuwe ontwikkelingen zoals JavaScript-frameworks en dynamische rendering brengen extra uitdagingen met zich mee voor effectieve implementatie van robots.txt en meta robots tags. Het is daarom belangrijk om je strategie regelmatig te evalueren en aan te passen.
Een toekomstbestendige aanpak vereist flexibiliteit en schaalbaarheid in je crawl- en indexbeheer. Dit betekent dat je systemen moet opzetten die gemakkelijk aangepast kunnen worden aan nieuwe technologieën en veranderende zoekmachine-richtlijnen. Automatisering kan hierbij helpen, maar menselijk toezicht blijft cruciaal voor strategische beslissingen.
De introductie van nieuwe crawlers, zoals die voor AI-training, vraagt om extra aandacht voor je robots.txt-configuratie en meta robots tags. Steeds meer websites implementeren bijvoorbeeld specifieke regels voor AI-crawlers, wat aantoont hoe belangrijk het is om op de hoogte te blijven van nieuwe ontwikkelingen en je strategie daarop aan te passen.
[Vervolg in deel 2 vanwege karakterlimiet]