De basis van interne duplicate content begrijpen
Interne duplicate content vormt een van de meest onderschatte uitdagingen in zoekmachineoptimalisatie. Deze vorm van contentduplicatie ontstaat wanneer dezelfde of sterk vergelijkbare inhoud via verschillende URL's binnen één website bereikbaar is. Volgens Google's documentatie kan dit de crawl-efficiëntie en rankings significant beïnvloeden, omdat zoekmachines moeite hebben met het bepalen welke versie als primair beschouwd moet worden.
De impact van interne duplicate content reikt verder dan alleen technische SEO-aspecten. Wanneer meerdere pagina's dezelfde inhoud bevatten, verdeelt de linkwaarde zich over deze pagina's, waardoor geen enkele versie optimaal kan presteren in de zoekresultaten. Bovendien verspilt Google waardevol crawl budget aan het indexeren van dubbele content, terwijl dit budget beter besteed kan worden aan het ontdekken van werkelijk unieke pagina's op je website.
Een belangrijk aspect dat vaak over het hoofd wordt gezien, is dat de 70% regel bij duplicate content herkenning bepaalt wanneer Google content als duplicaat beschouwt. Deze drempelwaarde helpt webmasters begrijpen wanneer contentoverlap problematisch wordt. Daarnaast speelt de context waarin duplicate content voorkomt een cruciale rol bij de beoordeling door zoekmachines.
Veelvoorkomende oorzaken van interne duplicatie
De oorzaken van interne duplicate content zijn divers en vaak technisch van aard. Een van de meest voorkomende bronnen vormen URL-parameters en duplicate content, waarbij filteropties en sorteerfuncties nieuwe URL-varianten genereren met dezelfde inhoud. Dit zie je bijvoorbeeld vaak bij webshops waar producten via verschillende navigatiepaden bereikbaar zijn.
Daarnaast ontstaat duplicate content regelmatig door technische configuraties zoals het ontbreken van een consequente keuze tussen www- en non-www-URL's. Content management systemen dragen ook bij aan het probleem door automatisch verschillende URL's te genereren voor dezelfde inhoud, bijvoorbeeld bij het gebruik van tags of categorieën. Bovendien zorgen printversies, mobiele versies en vertalingen zonder proper hreflang-implementatie voor onbedoelde duplicatie.
Een vaak onderschat probleem vormt de aanwezigheid van staging- of development-omgevingen die per ongeluk geïndexeerd worden. Deze omgevingen bevatten exacte kopieën van de live website en kunnen, wanneer ze niet correct afgeschermd zijn, leiden tot massale duplicate content issues. Tenslotte zorgen ook URL-parameters voor sessiebeheer en tracking regelmatig voor duplicatie van pagina's.
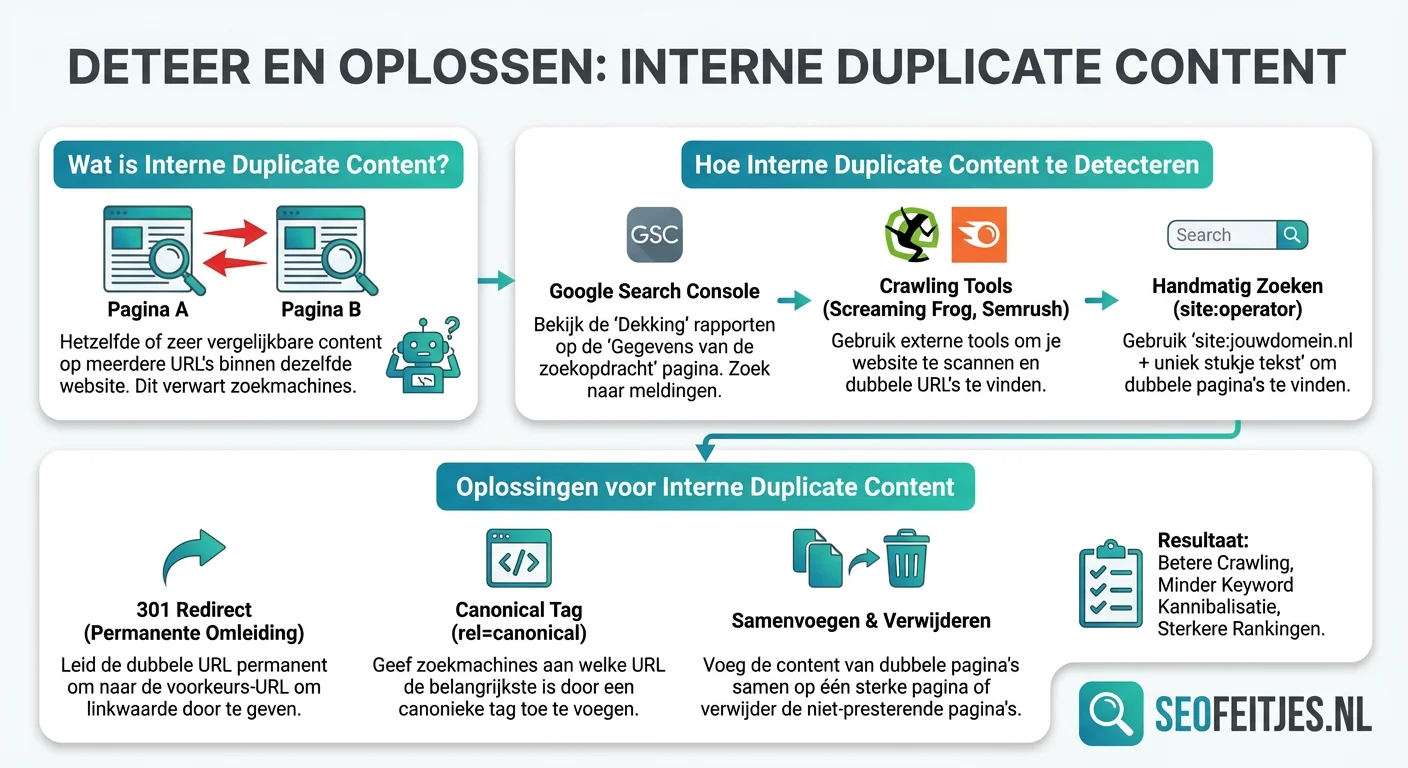
Detectiemethoden voor duplicate content
Het opsporen van interne duplicate content vereist een systematische aanpak met verschillende tools en technieken. Google Search Console biedt hiervoor essentiële inzichten via de Coverage-rapportage, waar je kunt zien welke pagina's Google als duplicaat beschouwt. Daarnaast helpen gespecialiseerde crawling tools zoals Screaming Frog bij het identificeren van exacte en bijna-identieke content.
Moderne SEO-tools bieden geavanceerde functionaliteit voor het vergelijken van contentoverlap. Ze analyseren niet alleen de zichtbare tekst, maar kijken ook naar de onderliggende HTML-structuur en metadata. Deze tools genereren clusters van vergelijkbare pagina's, waardoor je snel kunt bepalen welke content geconsolideerd moet worden. Bovendien helpen ze bij het identificeren van boilerplate content die onbedoeld tot duplicatie leidt.
Het is cruciaal om regelmatig handmatige steekproeven uit te voeren, omdat geautomatiseerde tools niet altijd context-specifieke duplicatie herkennen. Dit geldt vooral voor situaties waarin externe duplicate content door leveranciersbeschrijvingen zich mengt met interne duplicatie, wat extra complexiteit toevoegt aan het detectieproces.
Effectieve oplossingsstrategieën implementeren
Het oplossen van interne duplicate content vraagt om een doordachte strategie die verschillende technische maatregelen combineert. De implementatie van canonical tags vormt hierbij de hoeksteen van je aanpak. Deze tags wijzen zoekmachines naar de voorkeursversie van dubbele content, waardoor de linkwaarde geconsolideerd wordt op één URL. Het is echter essentieel om canonical tags consistent en correct te implementeren, omdat fouten in de implementatie juist tot meer verwarring kunnen leiden.
301-redirects bieden een permanente oplossing voor duplicate content die ontstaat door verschillende URL-structuren. Deze redirects sturen zowel bezoekers als zoekmachines automatisch door naar de canonieke versie van een pagina. Daarnaast spelen parameter-handling via Google Search Console en robots.txt een belangrijke rol bij het voorkomen van crawling van onnodige URL-varianten.
Content consolidatie vormt een effectieve maar arbeidsintensieve oplossing. Hierbij combineer je vergelijkbare content tot één sterke pagina die alle relevante informatie bevat. Dit vraagt om een zorgvuldige analyse van zoekintentie en gebruikerswaarde, maar levert uiteindelijk betere rankings op. Bovendien voorkom je hiermee het versnipperen van linkwaarde over meerdere vergelijkbare pagina's.
Preventieve maatregelen voor de toekomst
Het voorkomen van nieuwe duplicate content begint bij een doordacht contentbeheerproces. Implementeer daarom duidelijke richtlijnen voor contentcreatie waarin staat hoe om te gaan met hergebruik van content en wanneer nieuwe pagina's aangemaakt mogen worden. Train contentmanagers in het herkennen van potentiële duplicatie en het correct gebruiken van CMS-functionaliteit.
Technische preventie speelt een cruciale rol bij het vermijden van toekomstige duplicatie. Configureer je CMS zodanig dat het automatisch canonical tags toevoegt bij het gebruik van filters of categorieën. Implementeer daarnaast een systematische URL-structuur die duplicatie door verschillende navigatiepaden voorkomt. Zorg ook voor een robuuste redirect-strategie bij het verplaatsen of archiveren van content.
Regelmatige monitoring vormt het sluitstuk van je preventiestrategie. Gebruik tools als Google Search Console en log-analyse om nieuwe instances van duplicate content vroeg te signaleren. Plan periodieke content-audits waarin je specifiek zoekt naar contentoverlap en implementeer geautomatiseerde checks die waarschuwen bij het ontstaan van nieuwe duplicaten.
Impact op crawl budget optimaliseren
Het efficiënt gebruik van crawl budget wordt steeds belangrijker naarmate websites groeien. Interne duplicate content kan een significante impact hebben op hoe Google je site crawlt en indexeert. Door het aantal duplicaten te minimaliseren, zorg je ervoor dat Google's crawlers zich concentreren op je meest waardevolle pagina's.
Een strategische benadering van crawl budget management begint bij het identificeren van pagina's die echt geïndexeerd moeten worden. Gebruik noindex-tags voor pagina's die geen zoekwaarde hebben maar wel noodzakelijk zijn voor de gebruikerservaring. Configureer je XML sitemap zodanig dat deze alleen unieke, indexeerbare content bevat en update deze regelmatig om nieuwe duplicaten te voorkomen.
Het optimaliseren van je interne linkstructuur draagt bij aan efficiënt crawl budget gebruik. Vermijd het linken naar paginavarianten met parameters wanneer deze geen unieke waarde toevoegen. Implementeer een logische taxonomie die voorkomt dat content via verschillende paden bereikbaar is. Monitor daarnaast crawl statistieken in Google Search Console om te zien of je maatregelen effect hebben op de crawl efficiëntie.